MySQL笔记
mysql 由行和列之间建立某种关系存储数据信息,是最常见的关系型数据库,也是当下最流行的,开源的,免费的数据库
安装及配置
我习惯下载软件都会去官网进行下载,直接百度搜索 mysql 即可,mysql 的官网地址如下:
1 | |
当然也可以直接去他的下载地址:
1 | |
MySQL的下载页面如下所示:
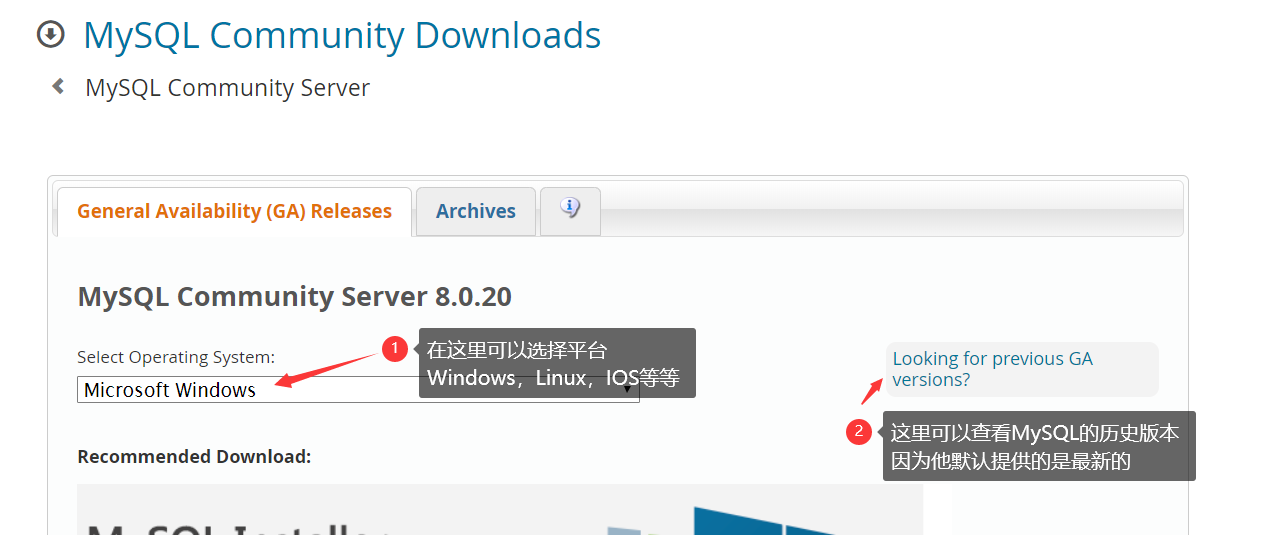
这里我选择下载的是 Windows x64 环境下的 MySQL 5.7.30,下载完成后是一个压缩包文件,将他解压到平时安装软件的位置就行了,解压就相当于是一种安装
MySQL 配置文件
在 mysql 解压完成后,进入 mysql 目录下,新建一个 mysql 的配置文件,命名要求及格式为my.ini,注意,这里的 ini 是文件的格式扩展名,而不是文件名的一部分
然后右键用记事本打开,在配置文件中添加如下的代码
1 | |
datadir是自己随便写的位置,目录名称也可以自行修改,但是最好是一个不存在的目录,这样在初始化的时候会为你自动创建该目录,如果是一个已存在的目录可能会出错
因为我们不是通过 MSI 进行安装的,并不能通过安装初始化 root 密码,所以在没有密码的状况下需要进设置无需密码登录,等所有设置都完成之后就可以注释掉了
配置文件就搞定了,这个是最简单的配置文件信息,mysql 配置信息远远不止这点,想要配置多去百度查询my.ini具体配置即可
配置环境变量
配置环境变量应该都很熟悉了
- 右键
计算机,点击属性 - 找到左侧的
高级系统设置,点击进入 - 在
高级选项卡下,点击下方的环境变量 - 在下面的
系统变量区域中找到PATH,双击进入 - 添加新的环境变量到 mysql 安装目录下的
bin目录中 - 至此,环境变量配置完成
初始化服务
这一步需要执行的只有两行代码,需要环境配置没有任何问题
1 | |
控制台提示Service successfully installed表示服务创建成功了,如果没有提示这个可能程序出现了问题,或者之前安装过 mysql 没有卸载干净,自行百度解决
1 | |
初始化本地数据库后,会在你之前设置的那个目录的位置创建一个你指定名称的目录,目录下会存放着数据库存储的文件,初始化命令执行会有几秒钟的延迟,请耐心等待,如果没有任何提示就证明初始化成功了
设置 ROOT 密码
启动 mysql 服务,打开控制台输入以下命令
1 | |
服务开启成功后,进入mysql:
1 | |
输入以上命令后,会提示让你输入密码,因为我们设置了无需密码登录,所以这里不输入任何字符直接回车,就可以进入 mysql( 日后若忘记了密码也可以这么找回 ),进入 mysql 后开始修改密码,流程如下:
1 | |
这样一套行云流水下来,root 的密码也设置好了,接下来去配置文件删掉最后一项,然后重启服务即可
注:上面涉及到修改密码的 update 语句,是基于mysql5.7.30版本使用的,如果版本低一些,请使用下面这行代码替换:
1 | |
这样一来你的 mysql 就已经配置完成啦!可以正常使用了
MIS 安装版忘记密码
之前在上面我们提过,如果我们忘记了密码可以回溯到最开始,在my.ini配置文件中使用skip-grant-tables即可无需密码登录,然后在重置密码
但是如果是通过 MIS 安装的 mysql,它的目录下是没有my.ini配置文件的,所以想要重置密码需要进行以下步骤:
-
关闭 mysql 的服务
-
在 cmd 下输入
mysqld --skip-grant-tables启动服务器 光标不动 (不要关闭该窗口) -
重新打开一个新的 cmd,键入命令
mysql -u root -p,输入密码的时候直接回车,没有校验 -
到这里就已经可以进入数据库了,在修改自己的密码即可:
use mysql;update user set authentication_string=password('密码') where user='root' and Host='localhost';
-
密码修改完成后,关闭两个 cmd 窗口 在任务管理器结束 mysqld 进程,重启 mysql 进程就可以正常使用了
结构化语言
学习 mysql 大多数都是在学习 sql 这门语言,sql 语言中划分了语句的类型,称之为结构化语言:
| 命令 | 作用 |
|---|---|
| DDL 数据定义语言 | 操作的是表结构相关,例如CREATE、ALTER、MODIFY、DROP |
| DML 数据操纵语言 | 操作表中具体的数据,例如INSER、DELETE、UPDATE、TRUNCATE |
| DQL 数据查询语言 | 负责查询相关的操作,例如SELECT、SHOW |
| DPL 事务处理语言 | 操作事务相关命令,例如BIGIN、ROLLBACK、COMMIT |
| DCL 数据控制语言 | 用于为用户设置权限的命令,例如GRANT、REVOKE |
库级相关命令
命令不用死记硬背,用时过来找,随时作补充,熟能生巧
1 | |
TEST代表库名称,` 被叫做 “飘号”,它适用于我们书写的标识符防止被识别为关键字
[ ] 中括号内的关键字为可选项:
CREATE DATABASE中的IF NOT EXISTS的作用是创建已存在的库时会防止报错DROP DATABASE中的IF EXISTS的作用是删除不存在的库时会防止报错CHARACTER SET表示的就是字符集了
表级相关命令
关于表的几个简单命令这里记一下:
1 | |
创建简单表
1 | |
各种数据类型
上面就是创建一张简单的数据表的 SQL 语句,ID和NAME都是列的名称,后面跟着的INT、VARCHAR就是数据类型,数据类型后面的括号代表的是长度,数据类型主要分为 数值 字符串 日期时间 枚举 三种
数值类型
| 类型 | 大小 | 最大数量 / 长度 | 使用场景 / 描述 |
|---|---|---|---|
| BIT | 位数据 | 1~64 | 小整数值 |
| TINYINT | 1 字节 | 255 | 小整数值 |
| SMALLINT | 2 字节 | 65535 | 大整数值 |
| MEDIUMINT | 3 字节 | 16777215 | 大整数值 |
| INT 或 INTEGER | 4 字节 | 2147483647 | 大整数值 |
| BIGINT | 8 字节 | 18446744073709551615 | 极大整数值 |
| FLOAT | 4 字节 | 单精度 浮点数值 | |
| DOUBLE | 8 字节 | 双精度 浮点数值 | |
| DECIMAL | (M, D) | 依赖于 M 和 D 的值 | 小数,适合金融计算 |
字符串类型
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 255 字节 | 定长字符串 |
| VARCHAR | 65535 字节 | 变长字符串 |
| TINYBLOB | 255 字节 | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 255 字节 | 短文本字符串 |
| BLOB | 65535 字节 | 二进制形式的长文本数据 |
| TEXT | 65535 字节 | 长文本数据 |
| MEDIUMBLOB | 16777215 字节 | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 16777215 字节 | 中等长度文本数据 |
| LONGBLOB | 4294967295 字节 | 二进制形式的极大文本数据 |
| LONGTEXT | 4294967295 字节 | 极大文本数据 |
日期时间类型
| 类型 | 大小 | 格式 | 用途 |
|---|---|---|---|
| DATE | 3 字节 | YYYY-MM-DD | 日期值 |
| TIME | 3 字节 | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 字节 | YYYY | 年份值 |
| DATETIME | 8 字节 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 字节 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
选择类型
| 类型 | 用途 |
|---|---|
| ENUM | 只能使用一些特定的值,例如 ENUM(‘男’, ‘女’) |
| SET | 如果说 ENUM 是单选,那么 SET 就是多选 |
根据了解到的数据类型完善一下表的结构
1 | |
约束 Constraint
表的数据肯定不是想些什么就写什么,不然数据乱了表就没有存在的意义了,要让表变得有意义,我们需要在向表中添加数据的时候设计一些规则,例如不能留空,或者不能重复之类的,这个叫做 约束
约束大致分为五种
-
主键约束
PRIMARY KEY- 在表中是唯一的标识,通过主键列可以找到任何一行记录,自带唯一和非空
-
外键约束
FOREIGN KEY- 指本表中的某一列关联其他表中的某一列,所取的值必须在被约束的列中存在,约束与被约束的列的类型以及长度必须相同 ( 阿里手册禁用外键约束 )
-
唯一约束
UNIQUE- 该列不允许出现重复的数据,NULL值除外
-
非空
NOT NULL- 该列不允许出现空值 NULL,空字符串 “” 不属于空值
-
检查
CHECK- 通过表达式判断来检查当前列是否符合要求的规则,该约束目前在 MySQL 中无效
约束的添加与查看
约束可以直接书写在类型的后面,叫做 行级约束,例如:
1 | |
也可以在表创建完成之后书写在最后面,叫做 表级约束,例如:
1 | |
表结构创建完成后,我们想知道自己究竟设置了那些约束,可以通过命令进行查看
1 | |
注意:
- 约束共有五种类型,分为表级约束和列级约束两种书写方式
- 表级约束不支持
NOT NULL,列级约束不支持FOREIGN KEY和CHECK - 个人建议使用 表级约束,使用表级约束的情况下查看所有关于约束的列可以直接看最后几行就一目了然了
有了这几个约束,我们在重新设计一下表结构
1 | |
列的各种属性
我们在创建表的时候,先是写列名称,然后是数据类型,然后是行级约束,最后写表级约束,列中除开这些之外,还有他本身自带的属性:
- 默认
DEFAULT- 向数据库中插入数据的时候,如果没有提供该列的数据,那么就是用这个默认值
- 注释
COMMENT- 注释是面向开发人员的,用来告诉开发人员这列代表什么意思,取值等等,表和列都可以使用
- 自增
AUTO_INCREMENT- 我们表中的主键列,当表中数据不多的时候可以选择使用自增,他会自动生成 1, 2, 3… 的递增主键
- 更新
ON UPDATE- 表中最常见的两个字段就是创建时间以及修改时间,其中修改时间是随着每次修改都更新的,这里就可以使用该属性来完成这个操作
- 填充
ZEROFILL- 如果当前字段长度为10,但是值得长度并不够10位,想要补全10为就可以用该属性
- 无符号
UNSIGNED- 适用于数值类型,只能存储大于等于 0 的值,简单理解 无符号 ≈ 无负号
关于自增的描述:
- 自增适用于数值类型且必须是主键的列,且一张表中只能有一个自增列
- 在 mysql 5.7 以及之前的版本,自增数据是暂存在内存中的,当重启 mysql 打开表后他会找到当前自增列的最大值开始继续自增,而 mysql 8 之后这个自增做了持久化
- 当我们向数据库中插入数据时,只有在未指定自增列的值或者传的值为 NULL 值得时候,才会触发自增
- 我们插入数据时为自增列 ( y ) 传了值 ( x ) 的情况下,如果 x > y 那么 x 就会作为新的自增值,否则不会变化
- 当前自增值为 1,执行了一次插入失败之后,在执行一次会发现值是 3,在失败的时候自增列还是会变化的
- 自增关于值得操作会在后面提到
根据掌握的属性在重新设计一次表结构
1 | |
修改已创建的表
上面每次做一写更新都会重新撰写建表语句,如果在项目已经上线的情况下,表中会有大量的数据,频繁的重建很浪费事件,所以我们需要学习修改已创建的表
重新创建一个测试表用来练习:
1 | |
表级修改
1 | |
列级修改
1 | |
约束修改
1 | |
自增修改
1 | |
对于已创建的表的修改,自始至终还是有些捉摸不透,建议还是通过可视化工具进行操作
扩展:三大范式
我们在书写一个程序的时候,设计数据库往往是最重要的一个环节,一个程序中的所有业务逻辑都是围绕着数据进行操作的,表结构设计的好程序写起来就省力一些,相反表结构设计的不好,程序写起来就比较麻烦,所以建议我们在设计数据库的时候参照一下数据库设计三大范式
第一范式:原子性
| 员工ID | 员工姓名 | 部门职位 | 员工薪资 |
|---|---|---|---|
| 4163545354 | 王富贵 | 技术部开发 | 8000 |
第一范式通俗来说就是表中的每列都不可再分,类似上面这张员工表,其中的部门职位可以进行拆分为部门和职位两列,违反了第一范式,应该按照下面的格式进行设计:
| 员工ID ( 主键 ) | 员工姓名 | 部门 | 职位 | 员工薪资 |
|---|---|---|---|---|
| 4163545354 | 王富贵 | 技术部 | 开发 | 8000 |
第二范式:完整性
一张表一般只有一个主键列用来区分每一行,但是有的表会使用到联合主键,第二范式就是要求所有列都要与主键列相关而不是和部分主键相关,例如下面张成绩表:
| 学生 ID ( 主键1 ) | 课程 ID ( 主键2 ) | 课程名称 | 分数 |
|---|---|---|---|
| 31718040101 | 82001 | 《Java高级从入门到入坟》 | 82 |
课程名称仅仅和课程 ID 有关系,与学生 ID 没有关系,这就违反了第二范式,应该将课程名称放到课程表中。
第三范式:直接关系
第三范式可以理解为*表中的每个字段都应该与主键有直接关系,而不是间接关系,*例如这张博客表中的分类名称就违反了第三范式,他应该是通过分类 ID 查出来的信息,不应该直接写到博客表中,应该写到分类表中
| 博客 ID ( 主键 ) | 分类 ID | 分类名称 | 博客标题 | 博客内容 |
|---|---|---|---|---|
| B348500012 | 2 | 知识 | Java入门教程 | Java是面向对象的高级语言… |
- 第三范式和第二范式很相像,第二范式是针对联合主键的,而第三范式是针对当前表和唯一主键的。
- 三大范式仅仅是一个规范,起到参考作用,但是在真实项目中要按照实际业务进行设计
数据的增删改查
简单练习CRUD
创建一张新的表用来进行测试:
1 | |
表肯定是要存储数据的,那么肯定就要有对数据的操作了,这里简单练习增删改查:
插入:INSERT
INSERT代表插入,INTO插入到T_EMP表,VALUES代表插入的具体的值
1 | |
查询:SELECT
SELECT代表查询*所有字段的值,FROM从T_EMP表中进行查询,WHERE代表过滤
1 | |
更新:UPDATE
UPDATE修改T_EMP表中的set姓名哈哈哈,WHERE要求修改ID为7的员工
1 | |
删除:DELETE
DELETE FROM删除T_EMP表中的数据,WHERE要求删除数据的ID为14
1 | |
条件查询与运算符
简单运算符主要分为两种
比较运算符:
- 【大于 >】【小于 <】【等于 =】【大于等于 >=】【小于等于 <=】【不等于 ( <> 或者 != ) 】
逻辑运算符:
- 【与 AND】【或 OR】【非 NOT】
特殊运算符
- 是否为空:【IS NULL】【IS NOT NULL】
- 包含以下任意一个值:IN ( 值,值,值 )
- 在
IN的括号中不仅可以书写特定的值,也可以查询列作为参数,被称为子表查询
- 在
- 满足在指定的区间内:
BETWEEN 最小值 AND 最大值;
WHERE 条件语句
上面有用到过WHERE,可以通过WHERE配合运算符来筛选出符合条件的数据进行操作
1 | |
更多查询操作
上面接触的比较运算符配合逻辑运算符可以完成大多数操作,这里继续学习更多的查询技巧
IN 包含
要求查询崔子希,朱咏娴,马庆炳,贾正经四个员工的信息
1 | |
使用OR关键字的确可以达到目的,但是使用IN的话可以极大简化SQL
1 | |
AS 别名
有些时候表中的列过多可能会造成查看失误,针对这点可以对每列在查询是起一个别名:
1 | |
BETWEEN AND 区间
查询年龄在20到50之前的员工
1 | |
LIKE 模糊查询
模糊查询,顾名思义,列中有部分匹配的内容就可以查询的到,模糊查询需要配合通配符使用,否则不起效果,MySQL中针对模糊查询有两个通配符:
_:下划线,只匹配一个字符%:百分号,匹配多个字符
1 | |
DISTINCT:去重 ( 了解 )
1 | |
我们发现了在员工表中有两个张楚岚,这里可以针对重复数据进行去重操作
1 | |
这回就可以看出重复数据已经不见了,但是只查询出了姓名不是我想要的,最起码要与ID一同查出来才可以,我们改一下SQL:
1 | |
发现了一个问题,ID列的确查询出来了,但是去重效果却消失了,这是因为按照上述写法,首先根据姓名进行判断是否重复,然后找到姓名重复的行再根据ID进行判断,ID不重复就代表数据没有重复
1 | |
这回更糟糕,SQL直接报错了,因为使用DISTINCT就必须放在查询开头,所以DISTINCT一般不用做真正的去重,可以根据他查询不重复数据的数量,如何进行去重操作也会在后面在提到
NULL值操作
如果实现查询所有没有留下手机号的员工,SQL应该这么写
1 | |
可实际效果却是一条都查不出来,那是因为NULL值是不参与运算的,这里需要使用IS NULL
1 | |
如果想查所有留了手机号的员工呢?之前逻辑运算中接触的NOT就用上了,它的作用就是取反
1 | |
排序与分页
我们在网页上操作一些表格数据的时候肯定使用过排序和分页的功能,这些都是前端发起的请求最终移交到数据库进行处理的,这里就学习一下排序与分页
ORDER BY:排序
排序有两种规则,一种是升序,一种是降序,分别对应着两个关键字:
ASC:升序,首行值最小,末行值最大DESC:降序,首行值最打,末行值最小
ORDER BY排序,根据SALARY字段进行ASC升序排序
1 | |
ASC升序排序是默认排序规则,所以可以省略不写,如果想倒排的话就需要写DESC
1 | |
可以多列同时排序,每个排序规则用逗号隔开,例如下面这段SQL
1 | |
LIMIT:分页
MySQL中分页使用的关键字为LIMIT,使用起来比较简单,如下所示
1 | |
LIMIT后面第一个参数是从第几条开始查,第二个参数是查询多少个数据,按照分页的逻辑只需要传入页码和查询数量就可实现分页查询,那么SQL应该修改为下面这种写法
1 | |
函数相关操作
先放一段落
1 | |